一、数据类型
基本类型
- byte/8
- char/16
- short/16
- int/32
- float/32
- long/64
- double/64
- boolean/~
boolean 只有两个值:true、false,可以使用 1 bit 来存储,但是具体大小没有明确规定。JVM 会在编译时期将 boolean 类型的数据转换为 int,使用 1 来表示 true,0 表示 false。JVM 并不支持 boolean 数组,而是使用 byte 数组来表示 int 数组来表示。
包装类型
基本类型都有对应的包装类型,基本类型与其对应的包装类型之间的赋值使用自动装箱与拆箱完成。
1 | Integer x = 2; // 装箱 |
Java中的不可变类型 与 可变类型
概念:不可变对象(Immutable Objects)即对象一旦被创建它的状态(对象的数据,也即对象属性值)就不能改变,反之即为可变对象(Mutable Objects)
不可变对象的特点:如果一个类符合以下特点,那么immutable
- 类的成员变量 应该是 immutable的 // 比如 基本数据类型 或者 包装类型
- 类的成员变量不能被修改
- 都被final修饰
- 都是 private的,且 没有提供setter方法
- 类不能被继承:被继承之后 可以添加setter或者能够改变类成员的方法
- 类被final修饰
- 使用静态工厂方法并且声明构造器为private
- 如果成员变量是可变类型(尽管被final修饰,这仅仅意味引用不可变,但是该成员对象内的成员可变),必须在向外部调用者提供该对象时 进行保护性拷贝
具体见例子代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49import java.util.Date;
// Planet是一个不可变类,因为当它构造完成之后没有办法改变它的状态
public final class Planet {
//声明为final的基本类型数据总是不可变的
private final double fMass;
//声明为final的不可变数据总是不可变的
private final String fName;
//Date是 可变类型 尽管被final修饰,这仅仅意味引用不可变,但是该对象内的成员可变
private final Date fDateOfDiscovery;
public Planet(double aMass, String aName, Date aDateOfDiscovery) {
fMass = aMass;
fName = aName;
//创建aDateOfDiscovery的一个私有拷贝
//这是保持fDateOfDiscovery属性为private的唯一方式, 并且保护这个
//类不受调用者对于原始aDateOfDiscovery对象所做任何改变的影响
fDateOfDiscovery = new Date(aDateOfDiscovery.getTime());
}
// 返回不可变对象(基本类型,String,包装类型...),外部的改变无法影响内部
public double getMass() {
return fMass;
}
public String getName() {
return fName;
}
/**
* 返回一个可变对象 - 好的方式.
*
* 返回属性的一个保护性拷贝.调用者可以任意改变返回的Date对象,但是不会
* 影响类的内部.为什么? 因为它们没有fDate的一个引用. 更准确的说, 它们
* 使用的是和fDate有着相同数据的另一个Date对象
*/
public Date getDateOfDiscovery() {
//外部调用者 尽管不能将该对象替换成另一个对象,但能修改对象的内部成员,不可取
//return fDateOfDiscovery;
//应该对原对象进行拷贝,生成一个新对象,从而外界的改变无法影响内部
return new Date(fDateOfDiscovery.getTime());
}
/**
* 测试方法
* @param args
*/
public static void main(String[] args) {
Planet planet = new Planet(1.0D, "earth", new Date());
Date date = planet.getDateOfDiscovery();
date.setTime(111111111L);
System.out.println("the value of fDateOfDiscovery of internal class : " + planet.fDateOfDiscovery.getTime());
System.out.println("the value of date after change its value : " + date.getTime());
}
Java中常见的不可变类型:
- 基本类型 是 可变类型/ 被final修饰 或者 不提供setter等改变其值的private基本类型是 不可变
- 基本类型的包装类型:Long , Float ,Integer
- String
- BigInteger ,BigDecimal // BigDecimal 从技术上讲不是不可变的, 因为它没有声明为final
类应该是不可变的,除非有很好的理由让它是可变的….如果一个类不能设计为不可变的,也要尽可能的限制它的可变性 — Effective Java // 应该尽量让一个类 成为不可变的,因为开发人员潜意识里总认为 引用不变即等于类不变,不可变类型 能够有效降低出错概率
缓存池
new Integer(123) 与 Integer.valueOf(123) 的区别在于:
- new Integer(123) 每次都会新建一个对象;
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。
1 | Integer x = new Integer(123); |
valueOf() 方法的实现比较简单,就是先判断值是否在缓存池中,如果在的话就直接返回缓存池的内容。
1 | public static Integer valueOf(int i) { |
在 Java 8/Java11 中,Integer 缓存池的大小默认为 -128~127。
1 | static final int low = -128; |
上述两种都已经过时,一般直接赋值即可,编译器会在自动装箱过程调用 valueOf() 方法,因此多个 Integer 实例使用自动装箱来创建并且值相同,那么就会引用相同的对象。
1 | Integer m = 123; |
基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。
StackOverflow : Differences between new Integer(123), Integer.valueOf(123) and just 123
二、String
概览
String 被声明为 final,因此它不可被继承。// final 类 不能被继承,String不可变的原因不是String是final类 而是 value数组是final 不可变的
在 Java 8 中,String 内部使用 char 数组存储数据。
1 | public final class String |
在 Java 9 之后 包括Java11,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。
1 | public final class String |
value 数组被声明为 final,这意味着 数组引用不可变。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
不可变的好处
1. 可以缓存 hash 值
因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
2. String Pool 的需要
如果一个 String 对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。

3. 安全性
String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
4. 线程安全
String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
Program Creek : Why String is immutable in Java?
String, StringBuffer and StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
StackOverflow : String, StringBuffer, and StringBuilder
在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String:不可变对象,Java中对String对象进行的操作实际上是一个不断创建新的对象并且将旧的对象回收的一个过程,所以执行速度很慢
String的优化
String str="abc"+"de"等价于String str="abcde", 此时快于 另外两者StringBuilder是线程不安全的,而StringBuffer是线程安全的
如果一个StringBuffer对象在字符串缓冲区被多个线程使用时,StringBuffer中很多方法可以带有synchronized关键字,所以可以保证线程是安全的,但StringBuilder的方法则没有该关键字,所以不能保证线程安全,有可能会出现一些错误的操作。所以如果要进行的操作是多线程的,那么就要使用StringBuffer,但是在单线程的情况下,还是建议使用速度比较快的StringBuilder
String Pool
参见虚拟机 运行时常量池内容
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定。不仅如此,还可以使用 String 的 intern() 方法在运行过程中将字符串添加到 String Pool 中。
当一个字符串调用 intern() 方法时,如果 String Pool 中已经存在一个字符串和该字符串值相等(使用 equals() 方法进行确定),那么就会返回 String Pool 中字符串的引用;否则,就会在 String Pool 中添加一个新的字符串,并返回这个新字符串的引用。
下面示例中,s1 和 s2 采用 new String() 的方式新建了两个不同字符串,而 s3 和 s4 是通过 s1.intern() 方法取得一个字符串引用。intern() 首先把 s1 引用的字符串放到 String Pool 中,然后返回这个字符串引用。因此 s3 和 s4 引用的是同一个字符串。
1 | String s1 = new String("aaa"); |
如果是采用 “bbb” 这种字面量的形式创建字符串,会自动地将字符串放入 String Pool 中。
1 | String s5 = "bbb"; |
在 Java 7 之前,String Pool 被放在运行时常量池中,它属于永久代。而在 Java 7,String Pool 被移到堆中。这是因为永久代的空间有限,在大量使用字符串的场景下会导致 OutOfMemoryError 错误。
new String(“abc”)
使用这种方式一共会创建两个字符串对象(前提是 String Pool 中还没有 “abc” 字符串对象)
- “abc” 属于字符串字面量,因此编译时期会在 String Pool 中创建一个字符串对象,指向这个 “abc” 字符串字面量;
- 而使用 new 的方式会在堆中创建一个字符串对象,并且将常量池中的字符串对象作为方法参数构造新对象。
- 两个对象的value数组实际是一个,但是两个对象引用不一样,是两个对象
以下是 String 构造函数的源码,可以看到,在将一个字符串对象作为另一个字符串对象的构造函数参数时,并不会完全复制 value 数组内容,而是都会指向同一个 value 数组。
1 | public String(String original) { |
三、运算
参数传递
详细内容参看上述知乎链接
Java 的参数是参数借由值传递方式传递,传递的值是个引用。(句中两个“值”不是一个意思,第一个值是evaluation result,第二个值是value content)
以下代码中 Dog dog 的 dog 是一个指针,存储的是对象的地址。在将一个参数传入一个方法时,本质上是将对象的地址以值的方式传递到形参中。因此在方法中使指针引用其它对象,那么这两个指针此时指向的是完全不同的对象,在一方改变其所指向对象的内容时对另一方没有影响。
第一个例子:基本类型
1 | void foo(int value) { |
第二个例子:没有提供改变自身方法的引用类型
1 | void foo(String text) { |
第三个例子:提供了改变自身方法的引用类型
1 | StringBuilder sb = new StringBuilder("iphone"); |
第四个例子:提供了改变自身方法的引用类型,但是不使用,而是使用赋值运算符。
1 | StringBuilder sb = new StringBuilder("iphone"); |
原理:
Java 的参数是参数借由值传递方式传递,传递的值是个引用/基本类型的话 就是值本身。

从虚拟机的角度来考虑这个问题,能有跟深刻的认识:
虚拟机中内存区域有 栈中的局部变量表和 堆, 方法的局部变量保存在方法的局部变量表中,一个方法显然不能获得其他方法的局部变量,也就是说,一个方法的局部变量生存期仅限于 方法内部
Java参数传递本质上是值传递(求值策略),但是这个值 一般是引用(值的内容)。
因此,值传递这个值本身在方法中进行修改是无效的,但是对于这个值所代表的对象进行修改,但是不修改这个值本身,那么修改是有效的。
因为 Java 这种参数传递 实际是:参数借由值传递方式传递,传递的值是个引用/基本类型的话 就是值本身这种特点,也可以将其参数传递方式 成为 Call by sharing,具有类似特点的还有 Python、Ruby、JavaScript等
StackOverflow: Is Java “pass-by-reference” or “pass-by-value”?
float 与 double
Java 不能隐式执行向下转型,因为这会使得精度降低。
1.1 字面量属于 double 类型,不能直接将 1.1 直接赋值给 float 变量,因为这是向下转型。
1 | // float f = 1.1; |
1.1f 字面量才是 float 类型。
1 | float f = 1.1f; |
隐式类型转换
因为字面量 1 是 int 类型,它比 short 类型精度要高,因此不能隐式地将 int 类型下转型为 short 类型。
1 | short s = 1; |
但是使用 += 或者 ++ 运算符可以执行隐式类型转换。
1 | s1 += 1; |
上面的语句相当于将 s1 + 1 的计算结果进行了向下转型:
1 | s1 = (short) (s1 + 1); |
StackOverflow : Why don’t Java’s +=, -=, *=, /= compound assignment operators require casting?
switch
从 Java 7 开始,可以在 switch 条件判断语句中使用 String 对象。
1 | String s = "a"; |
switch 不支持 long,是因为 switch 的设计初衷是对那些只有少数的几个值进行等值判断,如果值过于复杂,那么还是用 if 比较合适。
1 | // long x = 111; |
StackOverflow : Why can’t your switch statement data type be long, Java?
四、继承
访问权限
Java 中有四种访问权限,包括:三个访问权限修饰符:1. private、2. protected 以及 3. public,4. 如果不加访问修饰符,表示包级可见。
可以对类或类中的成员(字段以及方法)加上访问修饰符。
- 类可见表示其它类可以用这个类创建实例对象。
- 成员可见表示其它类可以用这个类的实例对象访问到该成员;
protected 用于修饰成员,不能修饰类,表示在继承体系中成员对于子类可见(protected 在子类中变为 private,对于子类的子类,protected成员不可见)。
设计良好的模块会隐藏所有的实现细节,把它的 API 与它的实现清晰地隔离开来。模块之间只通过它们的 API 进行通信,一个模块不需要知道其他模块的内部工作情况,这个概念被称为信息隐藏或封装。因此访问权限应当尽可能地使每个类或者成员不被外界访问。
如果在子类中重写父类的方法,那么子类中该方法的访问级别不允许低于父类的访问级别。这是为了确保可以使用父类实例的地方都可以使用子类实例,也就是确保满足里氏替换原则 (派生类(子类)对象可以代替其基类(超类)对象)。
字段决不能是公有的,因为这么做的话就失去了对这个字段修改行为的控制,客户端可以对其随意修改。例如下面的例子中,AccessExample 拥有 id 公有字段,如果在某个时刻,我们想要使用 int 存储 id 字段,那么就需要修改所有的客户端代码。
1 | public class AccessExample { |
可以使用公有的 getter 和 setter 方法来替换公有字段,这样的话就可以控制对字段的修改行为。
1 | public class AccessExample { |
但是也有例外,如果是包级私有的类或者私有的嵌套类,那么直接暴露成员不会有特别大的影响。
1 | public class AccessWithInnerClassExample { |
抽象类与接口
1. 抽象类
抽象类和抽象方法都使用 abstract 关键字进行声明。抽象类是指包含抽象方法的类,抽象类一般会包含抽象方法,抽象方法一定位于抽象类中。
抽象类和普通类最大的区别是,抽象类不能被实例化,需要继承抽象类才能实例化其子类。
1 | public abstract class AbstractClassExample { |
1 | public class AbstractExtendClassExample extends AbstractClassExample { |
1 | // AbstractClassExample ac1 = new AbstractClassExample(); |
2. 接口
接口是抽象类的延伸
在 Java 8 之前,它可以看成是一个完全抽象的类,也就是说它不能有任何的方法实现。如果一个接口想要添加新的方法,那么要修改所有实现了该接口的类,维护成本太高。
从 Java 8 开始,接口也可以拥有默认的方法实现。
接口的成员(字段 + 方法)默认都是 public 的,并且不允许定义为 private 或者 protected。
接口的字段默认都是 static 和 final 的。
1 | public interface InterfaceExample { |
1 | public class InterfaceImplementExample implements InterfaceExample { |
1 | // InterfaceExample ie1 = new InterfaceExample(); // 'InterfaceExample' is abstract; cannot be instantiated |
3. 比较
- 从设计层面上看,抽象类提供了一种 IS-A 关系,那么就必须满足里式替换原则,即子类对象必须能够替换掉所有父类对象。而接口更像是一种 LIKE-A 关系,它只是提供一种方法实现契约,并不要求接口和实现接口的类具有 IS-A 关系。
- 从使用上来看,一个类可以实现多个接口,但是不能继承多个抽象类。
- 接口的字段只能是 static 和 final 类型的,而抽象类的字段没有这种限制。
- 接口的成员只能是 public 的,而抽象类的成员可以有多种访问权限。
4. 使用选择
使用接口:
- 需要让不相关的类都实现一个方法,例如不相关的类都可以实现 Compareable 接口中的 compareTo() 方法;
- 需要使用多重继承。
使用抽象类:
- 需要在几个相关的类中共享代码。
- 需要能控制继承来的成员的访问权限,而不是都为 public。
- 需要继承非静态和非常量字段。
在很多情况下,接口优先于抽象类。因为接口没有抽象类严格的类层次结构要求,可以灵活地为一个类添加行为。并且从 Java 8 开始,接口也可以有默认的方法实现,使得修改接口的成本也变的很低。
抽象类与接口对比总结
- 抽象类:
- 定义:包含抽象函数的类
- 方法和变量可以是 private protected 和 public的
- 实现抽象类的类的对象需要满足里氏替换原则,单根继承结构 isA关系
- 接口:
- 定义:Java1.8之前是指 完全抽象的类 不允许有任何方法实现 Java1.8之后 允许有方法实现
- 方法和变量 都必须是 public 变量必须是final的
- 多继承 likeA关系
| 差别 | 抽象类 | 接口 |
| 根本 | 对类的抽象 | 对类行为的抽象 |
| 继承 | 单继承 | 多继承 |
| 成员 | 随意 | 必须为public 和 final的 |
| 函数 | 子类可以不实现/仍为抽象类 | 子类必须实现所有函数 |
| 随意 | 必须为public的 | |
| 可以有实现 | 方法不能有实现/default |
super
子类对象中的super关键字是一个指向其父类对象的一个指针
- 访问父类的构造函数:可以使用 super() 函数访问父类的构造函数,从而委托父类完成一些初始化的工作。
- 访问父类的成员:如果子类重写了父类的某个方法,可以通过使用 super 关键字来引用父类的方法实现。
1 | public class SuperExample { |
1 | public class SuperExtendExample extends SuperExample { |
1 | SuperExample e = new SuperExtendExample(1, 2, 3); |
1 | SuperExample.func() |
重写(覆盖)与重载
1. 重写(覆盖)(Override)
存在于继承体系中,指子类实现了一个与父类在方法声明上完全相同的一个方法。
为了满足里式替换原则,重写有以下两个限制:
- 子类方法的访问权限必须大于等于父类方法;(权限必须>=)
- 子类方法的返回类型必须是父类方法返回类型或为其子类型。(类型必须<=)
使用 @Override 注解,可以让编译器帮忙检查是否满足上面的两个限制条件
2. 重载(Overload)
- 方法名相同
- 参数列表不同(参数类型,顺序,个数,不包括参数名)
- 权限修饰符 和 返回值类型 相同与否 不作为判断条件
应该注意的是,返回值不同,其它都相同不算是重载。
3. 实例
1 | class A { |
1 | public class Test { |
涉及到重写时,方法调用的优先级为:
- this.show(O)
- super.show(O)
- this.show((super)O)
- super.show((super)O)
五、Object 通用方法
概览
1 | public native int hashCode() |
equals()
1. 等价关系
- 自反性
x.equals(x); // true - 对称性
x.equals(y) == y.equals(x); // true - 传递性
if (x.equals(y) && y.equals(z)) {x.equals(z)}; // true; - 一致性 多次调用 equals() 方法结果不变
x.equals(y) == x.equals(y); // true - 与 null 的比较: 对任何不是 null 的对象 x 调用 x.equals(null) 结果都为 false
2. 等价与相等
- 对于基本类型,== 判断两个值是否相等,基本类型没有 equals() 方法。
- 对于引用类型,== 判断两个变量是否引用同一个对象,而 equals() 判断引用的对象是否等价。
1 | Integer x = new Integer(1); |
3. 实现
- 检查是否为同一个对象的引用,如果是直接返回 true;
- 检查是否是同一个类型,如果不是,直接返回 false;
- 将 Object 对象进行转型;
- 判断每个关键域是否相等。
1 | public class EqualExample { |
hashCode()
hashCode() 返回散列值,而 equals() 是用来判断两个对象是否等价。等价的两个对象散列值一定相同,但是散列值相同的两个对象不一定等价。
在覆盖 equals() 方法时应当总是覆盖 hashCode() 方法,保证等价的两个对象散列值也相等。
下面的代码中,新建了两个等价的对象,并将它们添加到 HashSet 中。我们希望将这两个对象当成一样的,只在集合中添加一个对象,但是因为 EqualExample 没有实现 hasCode() 方法,因此这两个对象的散列值是不同的,最终导致集合添加了两个等价的对象。
1 | EqualExample e1 = new EqualExample(1, 1, 1); |
理想的散列函数应当具有均匀性, hashCode()方法中一般 将值通过以下公式计算:resul = result*31+x
一个数与 31 相乘 编译器会自动优化转换成移位和减法:31*x == (x<<5)-x
1 |
|
toString()
默认返回 ToStringExample@4554617c 这种形式,其中 @ 后面的数值为散列码的无符号十六进制表示
1 | public class ToStringExample { |
1 | ToStringExample example = new ToStringExample(123); |
1 | ToStringExample@4554617c |
如果两个类 互为 对方的成员, 那么在toString()方法中,直接使用对象,将会造成toString()循环引用,栈溢出
1 | public class A { |
clone()
1. cloneable
- clone() 是 Object 的 protected 方法,它不是 public的
- 一个类若需要能够提供clone方法,那么 需要
- 显式地public重写clone方法
- 实现 clonable 接口 (但是注意 clone方法不是clonable的方法,而是由Object类的protected方法)
- 若不实现clonable 接口 那么就会抛出 CloneNotSupportedException
- Object类中的clone方法是native方法,因此一个类显示声明的clone方法,首先需要 调用 object类的clone方法
- Object类的clone方法:将当前类中的成员变量进行拷贝
- 如果是基本类型,拷贝当前值
- 如果是引用,只是将当前引用的值进行拷贝,不会new一个新的对象
1 | public class CloneExample implements Cloneable { |
2. 浅拷贝与深拷贝
- 浅拷贝:拷贝对象和原始对象的引用类型引用同一个对象,如果原始对象进行修改,那么会影响新的拷贝对象
- 深拷贝:拷贝对象和原始对象的引用类型引用不同对象。
3. clone() 的替代方案
- 使用 clone() 方法来拷贝一个对象即复杂(类型转换)又有风险(抛出异常)
- 设计理念是链式调用父类的
clone方法,依赖于整个对象继承树的健壮性
- 设计理念是链式调用父类的
- Effective Java 书上讲到,使用拷贝构造函数或者拷贝工厂来替代clone()
1 | package com.leetcode; |
六、关键字
final
- final 基本数据类型 :final 使数值不变;
- final 引用:final 使引用不变,也就不能引用其它对象,但是被引用的对象本身是可以修改的。
- final 方法:声明方法不能被子类重写
- private 方法:private 方法隐式地被指定为 final,如果在子类中定义的方法和基类中的一个 private 方法签名相同,此时子类的方法不是重写基类方法,而是在子类中定义了一个新的方法
- final 类:声明类不允许被继承
static
1. 静态变量
- 静态变量:又称为类变量,也就是说这个变量属于类的,类所有的实例都共享静态变量,可以直接通过类名来访问它。静态变量在内存中只存在一份。
- 实例变量:每创建一个实例就会产生一个实例变量,它与该实例同生共死。
1 | public class A { |
2. 静态方法
静态方法必须有实现,也就是说它不能是抽象方法
原因:
- 静态方法在类加载的时候就存在了,它不依赖于任何实例,通过类可以直接访问
- 抽象方法需要被子类重写实现之后才能够使用,通过类不能使用抽象方法
- 前两点之间相互矛盾
方法中不能有 this 和 super 关键字:因为不依赖于实例,只能访问所属类的静态字段和静态方法
3. 静态语句块
静态语句块在类初始化时运行一次 类的生命周期:加载 验证 准备 解析 初始化 使用 卸载
4. 静态内部类
1. **非静态内部类依赖**于外部类的实例 需要使用 outclassObject.new
2. **静态内部类不依赖**于内部类的实例 不需要外部类对象实例
3. **静态内部类不能访问外部类的非静态的变量和方法**
1 | public class OuterClass { |
5. 静态导包
在使用静态变量和方法时不用再指明 ClassName,从而简化代码,但可读性大大降低。
1 | import static com.xxx.ClassName.* |
6. 初始化顺序
静态变量和静态语句块 : 按照 静态变量和静态语句块在类中出现顺序初始化
实例变量
类中的普通语句块
构造函数
存在继承的情况下,初始化顺序为:
父类(静态变量、静态语句块)
子类(静态变量、静态语句块)
父类(实例变量、普通语句块)
父类(构造函数)
子类(实例变量、普通语句块)
子类(构造函数)
七、反射
反射可以提供运行时的类信息,并且这个类可以在运行时才加载进来,甚至在编译时期该类的 .class 不存在也可以加载进来。
Class 类
三种获取方式
objectName.getClass();
Class.forName(className); // className是一个类名字符串
如果className所对应的类不存在,抛出ClassNotFoundException异常
ClassName.class
Class对象:
每个类都有一个 Class 对象,包含了与类有关的信息。当编译一个新类时,会产生一个同名的 .class 文件,该文件内容保存着 Class 对象
类加载相当于 Class 对象的加载,类在第一次主动引用时才动态加载到 JVM 中。也可以使用 Class.forName("com.mysql.jdbc.Driver") 这种方式来控制类的加载,该方法会返回一个 Class 对象
java.lang.reflect
Class 和 java.lang.reflect 一起对反射提供了支持,java.lang.reflect 类库主要包含了以下三个类:
- Field :可以使用 get() 和 set() 方法读取和修改 Field 对象关联的字段;
- Method :可以使用 invoke() 方法调用与 Method 对象关联的方法;
- Constructor :可以用 Constructor 创建新的对象。
Field,Method, Constructor都具有 getName()方法,都具有getModifiers方法,配合Modifier类中的isPublic,isPrivate,isFinal方法,判断一个方法或字段的修饰符
可以通过Class对象的getFields,getMethods和 getConstructors方法,得到类的public字段,方法,构造函数
可以通过Class对象的getDeclareFields,getDeclareMethods和 getDeclareConstructors方法,得到类的全部(包括私有)字段,方法,构造函数
反射机制默认受限于Java的访问权限控制,但是Field,Method,Constructor类都具有setAccessible方法修改访问权限
Filed类具有get方法 和 set方法 查看和设置 字段的值
Object get(Object obj)得到 obj对象中,Field字段的值,返回为Object,基本类型自动包装methodName.invoke(Object obj, Object args)方法
通过一个Method对象反射调用,对应的方法 其中 obj为调用方法所属的对象,如果是静态方法,obj==null,args 为 方法的参数
反射的优点:
- 可扩展性 :应用程序可以利用全限定名创建可扩展对象的实例,来使用来自外部的用户自定义类。
Class.forName("com.mysql.jdbc.Driver") - 类浏览器和可视化开发环境 :一个类浏览器需要可以枚举类的成员。可视化开发环境(如 IDE)可以从利用反射中可用的类型信息中受益,以帮助程序员编写正确的代码。
- 调试器和测试工具 : 调试器需要能够检查一个类里的私有成员。测试工具可以利用反射来自动地调用类里定义的可被发现的 API 定义,以确保一组测试中有较高的代码覆盖率。
- 总之一点,反射可以提供运行时信息,比如可以通过反射动态的调整数组的大小,AOP编程等等
反射的缺点:
尽管反射非常强大,但也不能滥用。如果一个功能可以不用反射完成,那么最好就不用。在我们使用反射技术时,下面几条内容应该牢记于心。
性能开销 :反射涉及了动态类型的解析,所以 JVM 无法对这些代码进行优化。因此,反射操作的效率要比那些非反射操作低得多。我们应该避免在经常被执行的代码或对性能要求很高的程序中使用反射。
安全限制 :使用反射技术要求程序必须在一个没有安全限制的环境中运行。如果一个程序必须在有安全限制的环境中运行,如 Applet,那么这就是个问题了。
内部暴露 :由于反射允许代码执行一些在正常情况下不被允许的操作(比如访问私有的属性和方法),所以使用反射可能会导致意料之外的副作用,这可能导致代码功能失调并破坏可移植性。反射代码破坏了抽象性,因此当平台发生改变的时候,代码的行为就有可能也随着变化。
八、异常
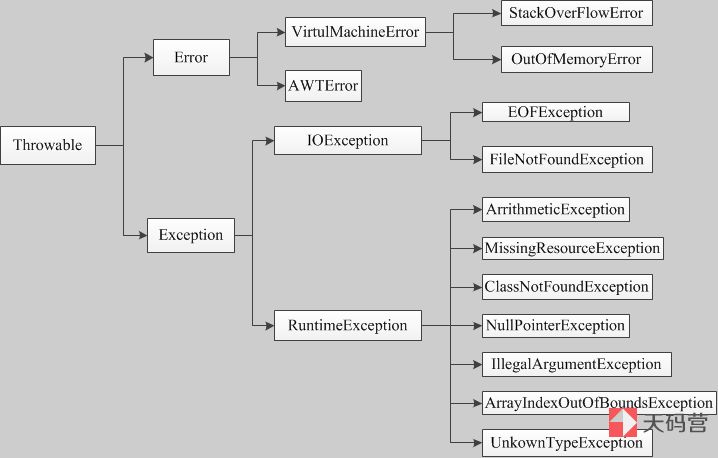
Java异常的分类与层级
- Throwable : 可以用来表示任何可以作为异常抛出的类
- Error: 用来表示 JVM 无法处理的错误
- Exception: 异常
- Runtime Exception :运行时异常,不受异常检查,导致程序崩溃,比如数组越界,和 被除数为0
- Checked Exception:受检查的异常,可以被修复,并且应该通过 try cache处理
九、泛型
泛型类
1
2
3
4
5
6public class Box<T> {
// T stands for "Type"
private T t;
public void set(T t) { this.t = t; }
public T get() { return t; }
}
泛型方法:返回类型前面加上一个类似
<K, V>的形式1
2
3
4
5
6public class Util {
public static <K, V> boolean compare(Pair<K, V> p1, Pair<K, V> p2) {
return p1.getKey().equals(p2.getKey()) &&
p1.getValue().equals(p2.getValue());
}
}边界符 :T extends Comparable
只能用于 继承了Comparable的类型,并且还将 bounds 信息 添加到编译后 1
2
3
4
5
6
7public static <T extends Comparable<T>> int countGreaterThan(T[] anArray, T elem) {
int count = 0;
for (T e : anArray)
if (e.compareTo(elem) > 0)
++count;
return count;
}PECS 原则 (producer extends,consumer super)
通配符
List<? extends T> listproducer extends : 使用通配符加上 extends 关键字。只能作为 producter,提供get()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class GenericReading {
static List<Apple> apples = Arrays.asList(new Apple());
static List<Fruit> fruit = Arrays.asList(new Fruit());
static class CovariantReader<T> {
T readCovariant(List<? extends T> list) {
return list.get(0);
}
}
static void f2() {
CovariantReader<Fruit> fruitReader = new CovariantReader<Fruit>();
Fruit f = fruitReader.readCovariant(fruit);
Fruit a = fruitReader.readCovariant(apples);
}
}consumer super : 通过通配符加上 super 关键字 只能作为 consumer,提供set()方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class GenericWriting {
static List<Apple> apples = new ArrayList<Apple>();
static List<Fruit> fruit = new ArrayList<Fruit>();
static <T> void writeExact(List<T> list, T item) {
list.add(item);
}
static void f1() {
writeExact(apples, new Apple());
writeExact(fruit, new Apple());
}
static <T> void writeWithWildcard(List<? super T> list, T item) {
list.add(item);
}
static void f2() {
writeWithWildcard(apples, new Apple());
writeWithWildcard(fruit, new Apple());
}
public static void main(String[] args) {
f1();
f2();
}
}类型擦除:类型擦除就是说Java泛型只能用于在编译期间的静态类型检查,然后编译器生成的代码会擦除相应的类型信息,这样到了运行期间实际上JVM根本就知道泛型所代表的具体类型。
没有 bounds
编译前
1
2
3
4
5
6
7
8
9
10public class Node<T> {
private T data;
private Node<T> next;
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
public T getData() { return data; }
// ...
}编译后: 泛型信息 全部 变为 Object
1
2
3
4
5
6
7
8
9
10public class Node {
private Object data;
private Node next;
public Node(Object data, Node next) {
this.data = data;
this.next = next;
}
public Object getData() { return data; }
// ...
}使用 bounds 边界符
编译前
1
2
3
4
5
6
7
8
9
10public class Node<T extends Comparable<T>> {
private T data;
private Node<T> next;
public Node(T data, Node<T> next) {
this.data = data;
this.next = next;
}
public T getData() { return data; }
// ...
}编译后: 泛型信息 替换为 bounds
1
2
3
4
5
6
7
8
9
10public class Node {
private Comparable data;
private Node next;
public Node(Comparable data, Node next) {
this.data = data;
this.next = next;
}
public Comparable getData() { return data; }
// ...
}
十、注解
Java 注解是附加在代码中的一些元信息,用于一些工具在编译、运行时进行解析和使用,起到说明、配置的功能。注解不会也不能影响代码的实际逻辑,仅仅起到辅助性的作用。
十一、特性
Java 各版本的新特性
New highlights in Java SE 8
- Lambda Expressions
- Pipelines and Streams
- Date and Time API
- Default Methods
- Type Annotations
- Nashhorn JavaScript Engine
- Concurrent Accumulators
- Parallel operations
- PermGen Error Removed
New highlights in Java SE 7
- Strings in Switch Statement
- Type Inference for Generic Instance Creation
- Multiple Exception Handling
- Support for Dynamic Languages
- Try with Resources
- Java nio Package
- Binary Literals, Underscore in literals
- Diamond Syntax
Java 与 C++ 的区别
- Java 是纯粹的面向对象语言,所有的对象都继承自 java.lang.Object,C++ 为了兼容 C 即支持面向对象也支持面向过程。
- Java 通过虚拟机从而实现跨平台特性,但是 C++ 依赖于特定的平台。
- Java 没有指针,它的引用可以理解为安全指针,而 C++ 具有和 C 一样的指针。
- Java 支持自动垃圾回收,而 C++ 需要手动回收。
- Java 不支持多重继承,只能通过实现多个接口来达到相同目的,而 C++ 支持多重继承。
- Java 不支持操作符重载,虽然可以对两个 String 对象执行加法运算,但是这是语言内置支持的操作,不属于操作符重载,而 C++ 可以。
- Java 的 goto 是保留字,但是不可用,C++ 可以使用 goto。
- Java 不支持条件编译,C++ 通过 #ifdef #ifndef 等预处理命令从而实现条件编译。
What are the main differences between Java and C++?
JRE or JDK
- JRE is the JVM program, Java application need to run on JRE.
- JDK is a superset of JRE, JRE + tools for developing java programs. e.g, it provides the compiler “javac”
参考资料
- Eckel B. Java 编程思想[M]. 机械工业出版社, 2002.
- Bloch J. Effective java[M]. Addison-Wesley Professional, 2017.

